To implement some algorithms that involve graph traversal, and in so doing get experience with using the Graph, Stack, Queue, and Priority Queue ADTs.
In this activity you will write a single class with at least three static methods, each one implementing a particular algorithm that computes some property of a given graph. (You will also write a main method that tests your algorithm implementations.)
This is an extended, ungraded pair-programming activity. We're going to take a while working together to learn about these algorithms and ADTs. Beyond the pair programming (which is required unless you have excused absences from class), please use whatever resources and approaches that will best help you learn.
The code that you write for this assignment will build on top of a variety of ADT interfaces and implementations (including Graph, List, Stack, Queue, and Priority Queue). I made a single zip file with all the code you'll need, so please download that.
Just for the sake of completeness, here are direct links to all the ADT interface files (and one class source file) included in the zip file:
If you need it, here's the complete list of class files contained in the zip file. You may also find the Javadoc documentation useful.
To start this activity, create a single file (with an empty class inside it) called GraphTraversal.java. Remember to put your and your partner's name at the top! Each of the following sections describes a problem that can be solved using graph traversal, and describes an algorithm that solves it. Implement each algorithm in a static method with the name and signature given in that section.
A general requirement of this set of activities is that you are allowed to write only static methods. The class GraphTraversal cannot have any non-static data members or methods; it is meant only as a container for the functions that you write. You may write static helper methods if you'd like, but the class should hold no state and no code you write should create any instances of the GraphTraversal class. In addition, you may not write any additional classes, nor use any of Java's built-in container types. (This is all fairly contrary to Java's object-oriented design philosophy, but graph algorithms are much clearer if you write them in a functional style.)
Before you write each algorithm, you will design a few test cases for it and then write them up in your main method.
The Problem
This activity will be a first (ultimately unsuccessful) attempt at solving the “Shortest $s$–$t$ Path“ problem — we'll return to the problem in Activity 3. This problem is defined for a weighted graph, except that we consider the weights to be “lengths” instead: a low value assigned to an edge means it's a “short” edge, and a high value means it's a “long” edge.
Given a weighted graph and two chosen nodes (which we'll call $s$ and $t$), we want to compute the path from $s$ to $t$ with the lowest possible total length. (Note that this is different from the total number of edges; we're trying to minimize the total weight/length of all the edges in the path, even if that requires many edges.)
The Algorithm
Given a weighted graph $G = (V, E, w)$ and two vertices $s$ and $t$ in that graph, we will compute a sequence of vertices representing a path from $s$ to $t$. We will “greedily” attempt to make it a “short” one — that is, one with low total weight. (In the end, we'll find that the greedy approach doesn't succeed.) Here's how the algorithm works:
- Let $n = |V|$.
- Create an empty list called $P$.
- Create a list, $M$, of length $n$.
- Set $M[i] = \text{False}$ for all $i = 0, 1, 2 \ldots (n-1)$.
- Set $M[s] = \text{True}$ and append $s$ to the end of $P$.
- While the vertex at the end of $P$ is not $t$:
- Get the vertex at the end of $P$ and call it $a$.
- Let $b$ be the neighbor of $a$ for which $M[b] = \text{False}$ and $w(a,b)$ is minimized.
- If no such neighbor $b$ exists:
- Terminate the algorithm with an error.
- Set $M[b] = \text{True}$ and append $b$ to the end of $P$.
- Return $P$.
Work with your partner to think through this algorithm on a few different example graphs. Answer the following questions on a sheet of paper:
- Is this algorithm well-defined for both undirected and directed graphs? Is its logic fundamentally the same in either case?
- Create a graph on which the algorithm will correctly return the shortest $s$–$t$ path.
- Create a graph where the path it returns is not the shortest. How did you trick it?
- What do we mean when we say that this algorithm is “greedy”?
- Create a graph where the algorithm terminates with an error. Can you state in general what will cause an error? (In other words, what would be a good comment to add to that line where we terminate with an error?)
- How do we know that this algorithm will terminate (that is, that it won't run forever)?
Your Implementation Instructions
To implement the above algorithm in Java, you will write a method with the following interface:
/**
* Tries to compute a list of vertices forming a short s-t path. This
* method can be tricked into returning a path that is not the shortest
* possible, and it may not find a path at all, but it will work greedily to
* make a short path.
*
* @param G The graph in which to search.
* @param sourceNode The ID of a node in G: the starting point of the path.
* @param targetNode The ID of a node in G: the ending point of the path.
*
* @return A List of node IDs forming a path from sourceNode to targetNode.
*
* @throws RuntimeException if the algorithm fails to find a short path to
* targetNode.
*/
public static List<Integer> greedyShortPath(
WeightedGraph G, int sourceNode, int targetNode)
- Copy that method interface and fill in a stub body, just enough to get it to compile. (In particular, in this case you should just immediately return an empty list.)
-
Before you write your implementation, design a thorough set of tests on paper, and then write them in your code to run from the main method. A test consists of an input, an expected output, and, when executed, a comparison to the actual output computed by the implementation. Note that you can and should write your tests before you write your implementation.
Working on paper, try to come up with example graphs that will demonstrate the different expected behaviors of the algorithm, and also come up with challenging graphs that might expose bugs. (Remember that big things are challenging for humans, but usually not for computers! Your goal is to come up with devious examples, not necessarily big or complex ones.) Think about edge cases — empty graphs, singletons, fully disconnected graphs, graphs with many connected components, trees, complete graphs, etc.
- Now fill out your implementation of
greedyShortPath(). Note that the algorithm was described in prose using mathematical notation, so the variable names are very short, as is standard in math. When you implement it in code, you should use descriptive variable names.
Hint: to keep your code clean and organized, you'll probably want to create separate functions for producing example graphs. Here's one I wrote:
public static WeightedGraph makeExampleGraph() {
boolean directed = true;
int numNodes = 5;
WeightedGraph G = new MysteryWeightedGraphImplementation(directed, numNodes);
G.addEdge(2, 0, 8.0);
G.addEdge(3, 4, 1.5);
// ... and so on ...
return G;
}
Hint: take a look at the Javadoc documentation for getNeighbors(). It returns an Iterable<Integer>. An Iterable is just something that you can write a for-each loop over. So here's how, given an node ID that we'll call node, you can loop over all its neighbors in a graph G:
for(Integer neighbor : G.getNeighbors(node)) {
// ... do something with the node "neighbor".
}
The Problem
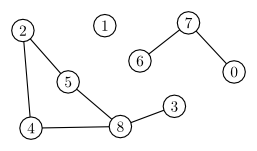
This is the task of computing the set of all the vertices in the connected component of a given vertex. For example, in the following graph, the connected component that includes vertex 5 is the vertex set $\{5, 8, 3, 2, 4\}$:
The Algorithm
Given a graph $G = (V, E)$ and a vertex $s$ in that graph, an algorithm to compute the connected component of $s$ may be built on top of breadth-first search. Here's how it works:
- Let $n = |V|$.
- Create an empty queue called $Q$.
- Create a list, $D$, of length $n$.
- Set $D[i] = -1$ for all $i = 0, 1, 2 \ldots (n-1)$.
- Set $D[s] = 0$ and enqueue $s$ in $Q$.
- While $Q$ is not empty:
- Dequeue a vertex from $Q$ and call it $v$.
- For each neighbor $u$ of $v$:
- If $D[u] = -1$, set $D[u] = D[v] + 1$ and enqueue $u$ in $Q$.
- We have now computed the connected component of $s$: each vertex $i$ for which $D[i] \ge 0$ is in $s$'s connected component.
Take a few minutes to think through why this algorithm works.
- What makes this a breadth-first search? (The answer is more fundamental than “it uses a queue”.)
- What do the values in $D$ mean?
- How do we know that all the vertices in $s$'s connected component have been given a non-negative value in $D$ by the time the while loop exits?
- How do we know that this algorithm will terminate (that is, that it won't run forever)?
Your Implementation Instructions
To implement the above algorithm in Java, you will write a method with the following interface:
/**
* Finds all vertices in the connected component of a given node.
*
* Prerequisite: The graph G is undirected.
*
* @param G The graph in which to search.
* @param targetNode The ID of a node in G.
*
* @return A List of node IDs (with no repeats) of the nodes in G that are
* in targetNode's connected component.
*/
public static List<Integer> connectedComponent(Graph G, int targetNode)
- Copy that method interface and fill in a stub body, just enough to get it to compile. (In particular, in this case you should just immediately return an empty list.)
-
Before you write your implementation, design a thorough set of tests on paper, and then write them in your code to run from the main method. A test consists of an input, an expected output, and, when executed, a comparison to the actual output computed by the implementation. Note that you can and should write your tests before you write your implementation.
Working on paper, try to come up with example graphs that will demonstrate the different expected behaviors of the algorithm, and also come up with challenging graphs that might expose bugs. (Remember that big things are challenging for humans, but usually not for computers! Your goal is to come up with devious examples, not necessarily big or complex ones.) Think about edge cases — empty graphs, singletons, fully disconnected graphs, graphs with many connected components, trees, complete graphs, etc.
- Now fill out your implementation of
connectedComponent(). Note that the algorithm was described in prose using mathematical notation, so the variable names are very short, as is standard in math. When you implement it in code, you should use descriptive variable names.
As above, the variable names in the pseudocode above are very “mathy”, rather than “source-codey”. Use descriptive variable names in your implementation.
An Extra Challenge
This step is optional; it's just here for fun if you want to try implementing an extra feature.
Create another method that computes all of a graph's connected components:
/**
* Computes and returns all the connected components of a graph.
*
* @param G The graph in which to search.
*
* @return A List of Lists of node IDs. Each inner list represents a single
* connected component of G: its contents are the IDs (with no repeats) of all
* the nodes in the component. The full output accounts for every node in G,
* and lists each node only once.
*/
public static List<List<Integer>> allConnectedComponents(Graph G)
The algorithm to do this involves just a small modification to the single-component algorithm given above. Try to write it as efficiently as possible, and don't do it by making repeated calls to connectedComponent(). Think carefully about the worst-case asymptotic running-time order for your function; it should be the same as for the worst case for connectedComponent().
The Problem
This is the task of computing a set of vertices that form a cycle somewhere in the connected component of a given vertex. For example, in the following graph, the cycle $(2, 4, 8, 5)$ is in the connected component that includes vertex 3:
The Algorithm
Given an undirected graph $G = (V,E)$ and a vertex $s$ in that graph, an algorithm to detect a cycle in $s$'s connected component (if there is one) may be built on top of depth-first search. Here's how it works:
First, set everything up to do the search:
- Let $n = |V|$.
- Create an empty stack called $S$.
- Create a list, $P$, of length $n$.
- Set $P[i] = -1$ for all $i = 0, 1, 2 \ldots (n-1)$.
- Set $P[s] = s$ and push $s$ onto $S$.
- Let $c = -1$.
Then search the graph for a cycle:
- While $S$ is not empty and $c = -1$:
- Pop a vertex from the top of $S$ and call it $v$.
- For each neighbor $u$ of $v$:
- If $P[u] = -1$:
- Set $P[u] = v$.
- Push $u$ onto $S$.
- Otherwise, if $u \ne P[v]$:
- Set $c = u$.
- Set $P[P[u]] = u$.
- Set $P[u] = v$.
- Immediately break out of the for loop.
Finally, reconstruct the cycle from the values you computed.
- If $c = -1$, then there are no cycles in $s$'s connected component, and we're done.
- Otherwise, the values in $P$ tell us how to walk backward around the cycle from $c$. So:
- Create an empty list, $C$.
- Add $c$ to the end of the list, and let $v = P[c]$.
- While $v \ne c$:
- Add $v$ to the end of the list.
- Let $v = P[v]$.
- Return $C$.
Take a few minutes to think through why this algorithm works.
- What makes it a depth-first search?
- How do we know that this algorithm will terminate (that is, that it won't run forever)?
- What do the values stored in $P$ mean?
- How do we know, when we perform the “Otherwise, ...” step, that the vertex $c$ is a member of a cycle?
- Why do we have to check the condition $u \ne P[v]$ before we decide that? (What would happen if we didn't check?)
- How can we be certain that we'll never report a cycle if no cycle exists in $s$'s connected component?
- How can we be certain we'll find a cycle if there is one to be found in $s$'s connected component?
- What if we wrote this for a directed graph $G$ instead? Which part of the code could we leave out? What sort of cycle would we fail to detect if we didn't remove that bit of code?
- Is it possible to modify DFS (without changing the asymptotic running-time order) so that it finds all cycles in a graph?
Your Implementation Instructions
You will implement the above algorithm in a method with the following signature:
/**
* Computes and returns a list of vertices in some cycle in the connected
* component of a specified vertex in an undirected graph.
*
* @param G The undirected graph in which to search.
* @param targetNode The ID of a node in G.
*
* @return An empty list if there are no cycles in targetNode's connected
* component. Otherwise, a list of node IDs (with no repeats), in order, around
* some cycle. There is an edge between the first and last nodes in this list.
*/
public static List<Integer> findCycle(Graph G, int targetNode)
- Copy that method interface and fill in a stub body, just enough to get it to compile. (In particular, in this case you should just immediately return an empty list.)
-
Before you write your implementation, design a thorough set of tests on paper, and then write them in your code to run from the main method. A test consists of an input, an expected output, and, when executed, a comparison to the actual output computed by the implementation. Note that you can and should write your tests before you write your implementation.
Working on paper, try to come up with example graphs that will demonstrate the different expected behaviors of the algorithm, and also come up with challenging graphs that might expose bugs. (Remember that big things are challenging for humans, but usually not for computers! Your goal is to come up with devious examples, not necessarily big or complex ones.) Think about edge cases — empty graphs, singletons, fully disconnected graphs, graphs with many connected components, trees, complete graphs, etc.
- Now fill out your implementation of
findCycle(). Note that the algorithm was described in prose using mathematical notation, so the variable names are very short, as is standard in math. When you implement it in code, you should use descriptive variable names.
This activity is HW4. It is laid out as a regular activity below; please see the homework assignment for details on how to do this as an assignment.
The Problem
Given a single starting node $s$, this is the task of computing the distance from $s$ to each node in a weighted graph. In a weighted graph, the “length” of a path in a weighted graph is the sum of the weights of the edges along that path. A “shortest $s–t$ path” is a path from $s$ to $t$ whose length is the minimum out of all $s–t$ paths. The “distance” from $s$ to $t$ is this minimum length.
(There are several variations on this problem. An upgraded version instead asks us to compute a shortest $s–v$ path for all $v$ in the graph, rather than just the length of this path. The algorithm below can be upgraded to solve this problem instead. In addition, a more limited version of the problem specifies two vertices, $s$ and $t$, and asks just for a shortest $s–t$ path, or just the length of this path.)
The Algorithm
Given an unweighted graph (directed or undirected) $G = (V,E)$ with non-negative weighting function $w$, and a vertex $s$ in that graph, the Single-Source Shortest Paths problem is solved by Dijkstra's Algorithm:
- Create a list $D$ and set $D[v] = +∞$ for all $v$. Set $D[s] = 0$.
- Create an updatable min-priority queue $P$ and enqueue $(v, D[v])$ into it for all $v$.
- While the min priority in $P$ is finite:
- Dequeue $(v, b)$ from $P$.
- Set $D[v] = b$.
- For each neighbor $u$ of $v$:
- If $D[u] = +∞$:
- Let $c$ be the current priority of $u$ in $P$.
- If $D[v] + w(v,u) < c$:
- Update $u$'s priority in $P$ to $D[v] + w(v,u)$.
Take a few minutes to think through why this algorithm works.
- How is this algorithm different from BFS and DFS? How is it similar?
- Could we instead use BFS or DFS to solve the shortest-path problem? Why or why not?
- How do we know that this algorithm will terminate?
Your Implementation Instructions
You and your partner will submit your work for this activity for credit — this will be a 25-point assignment. Your work will be evaluated based on the quality of your tests, the correctness and robustness of its implementation (that is, whether it gets the right answer for a variety of inputs, including tricky edge cases), and the organization and style of your code. There is also a small extension that counts for one point.
You will implement the above algorithm in a method with the following signature:
/**
* Computes single-source shortest path distances. Given graph G and vertex
* s, computes the length of the shortest path from s to each node in G. G
* is a weighted graph, but may be directed or undirected.
*
* @param G The graph in which to search.
* @param source The ID of the node from which distances will be computed.
*
* @return A List of length G.numVerts(), whose entry at index u is the
* distance from source to u.
*/
public static List<Double> ssspDistances(WeightedGraph G, int source)
- Copy that method interface and fill in a stub body, just enough to get it to compile. (In particular, in this case you should just immediately return an empty list.)
-
Before you write your implementation, design a thorough set of tests on paper, and then write them in your code to run from the main method. A test consists of an input, an expected output, and, when executed, a comparison to the actual output computed by the implementation. Note that you can and should write your tests before you write your implementation.
Working on paper, try to come up with example graphs that will demonstrate the different expected behaviors of the algorithm, and also come up with challenging graphs that might expose bugs. (Remember that big things are challenging for humans, but usually not for computers! Your goal is to come up with devious examples, not necessarily big or complex ones.) Think about edge cases — empty graphs, singletons, fully disconnected graphs, graphs with many connected components, trees, complete graphs, etc. Don't bother testing invalid input; that's not the point.
- Now fill out your implementation of
ssspDistances(), as always using descriptive variable names and comments.
Extension: Compute Paths, Not Just Distances
For your final two points on this assignment, test and implement another function, with the following interface:
/**
* Computes single-source shortest paths. Given graph G and vertex s,
* computes a shortest path from s to each node in G. G is a weighted
* graph, but may be directed or undirected.
*
* @param G The graph in which to search.
* @param source The ID of the node from which distances will be computed.
*
* @return A List of length G.numVerts(), whose entry at index u is a list
* of vertices forming a path from source to u. If no such path
* exists, the list for u is empty.
*/
public static List<List<Integer>> shortestPaths(WeightedGraph G, int source)