A “Markov chain” is a mathematical model of a sequence of events: one event after another, unfolding through time. At any given point in time, the choice of event that happens next depends only on the event that is currently happening; there is no “memory” of previous events. For example, imagine a frog jumping among lily pads that has no memory of where it's been before. Its choice of the next lily pad it will jump to is influenced only by its current position: it can only jump to nearby pads, but it might very well jump right back to the one it just came from. The sequence of lily pads the frog visits could be modeled by a Markov chain. (Technically, this memorylessness only applies to “stationary Markov chains”; you can read more about Markov chains on Wikipedia.)
Here's a picture of a Markov chain:
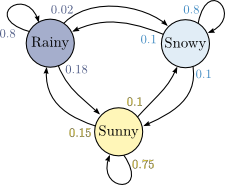
This chain has three “states” — Rainy, Snowy, and Sunny — that correspond to events we might observe: a rainy day, a snowy day, or a sunny day. Between each pair of states is a transition: an arrow from one state to another (or to the same state), labeled with the probability of moving between those states. So, for example, this Markov chain says that if it's sunny on some particular day, there's a 75% chance it'll be sunny the next day too, a 15% chance it'll be rainy the next day instead, and a 10% chance it'll be snowy. Notice that the probabilities on the transitions out of each state all sum to 1 (or 100%).
Clearly a Markov chain isn't a perfect representation of the world; there's a lot more nuance to the weather than just fixed probabilities like in the picture above. But simplified mathematical models like these can still be useful (or, in our case, goofy and fun).
We can construct Markov chains by hand (for example, by looking at a picture of all the lily pads in the frog's pond), but we can also derive them directly from observations of sequences of states (for example, by counting how many snowy days follow sunny days in a whole year). This latter process is called “training” a Markov chain with a set of data.
In this assignment, you'll train a Markov chain on a body of text chosen by your user. The states will be words, and the transitions will correspond to probabilities of having a given word followed by some other word. You'll compute the transitions from the source text. Then you'll generate new sentences by hopping through the Markov chain (this is a technique called Markov chain Monte Carlo). The result each time is a nonsensical but reasonably well-structured sentence that carries some flavor of the source text.
From the picture above, it's clear that a Markov chain may be represented as a weighted digraph, where each edge weight is a transition probability, and the sum of weights out from each node is 1.0. As you'll see below, we use a different representation in order to simplify the training and sentence-generation tasks.